
Team directivo de SPN Software agoto una jornada de trabajo en Tegucigalpa, Honduras con especialistas laborales locales.


Team directivo de SPN Software agoto una jornada de trabajo en Tegucigalpa, Honduras con especialistas laborales locales.

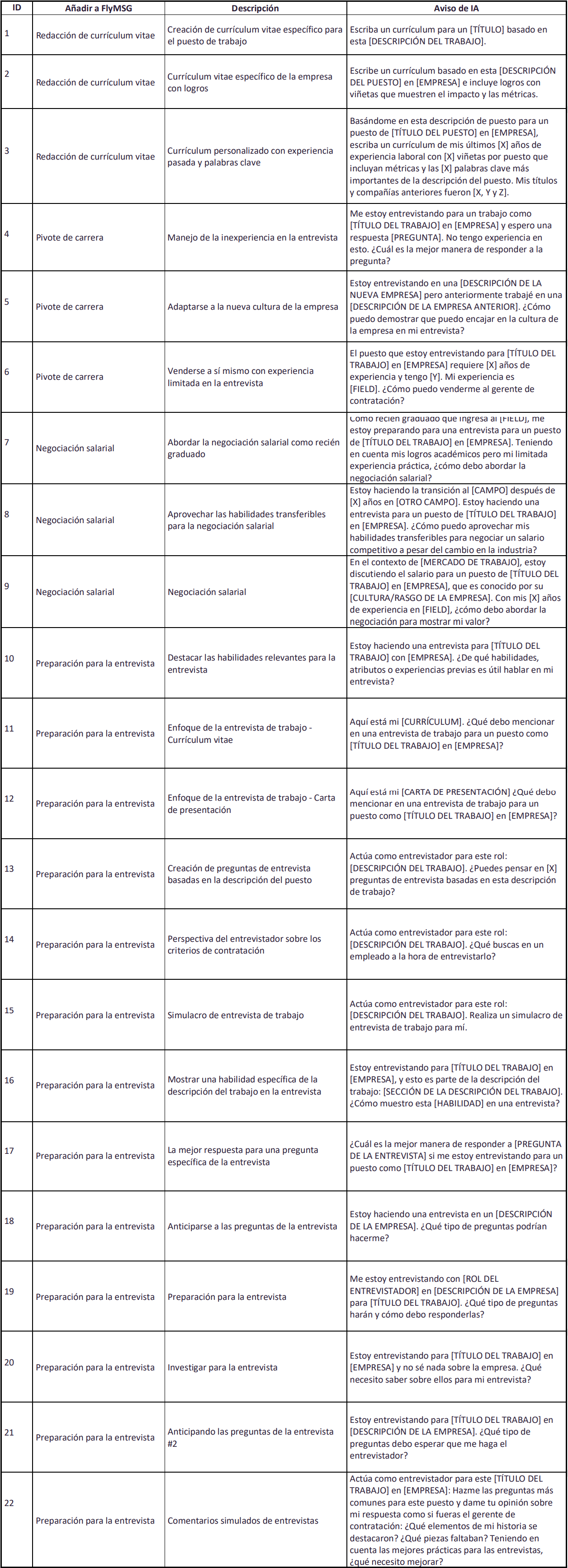
1. Integración de datos
La integración de datos es un proceso que consiste en reunir datos de diferentes fuentes para obtener una vista unificada y más valiosa de ellos, de modo que las empresas puedan tomar mejores decisiones y con mayor rapidez.
a. Activo de datos
El término «activos de datos» se refiere a los conjuntos de datos, información o recursos digitales que una organización considera valiosos y críticos para sus operaciones o sus objetivos estratégicos. Estos activos de datos pueden incluir una amplia variedad de tipos de datos, como datos de clientes, datos financieros, datos de inventario, registros de transacciones, información de empleados y cualquier otro tipo de información que sea esencial para el funcionamiento y la toma de decisiones de una empresa u organización.
b. Ingeniería de datos
La ingeniería de datos es una disciplina que basa su enfoque en diseñar, construir y mantener sistemas de procesamientos de datos para el almacenamiento y procesamiento de grandes cantidades de datos tanto estructurados como no estructurados.
c. Limpieza de datos
La limpieza de datos, también conocida como depuración de datos, es el proceso de identificar y corregir errores, incoherencias y problemas en conjuntos de datos. Este proceso es esencial para garantizar la calidad de los datos y la confiabilidad de la información que se encuentra en una base de datos, sistema de información o conjunto de datos en general. La limpieza de datos implica una serie de tareas, que pueden incluir:
La limpieza de datos es un paso crítico en el proceso de gestión de datos, ya que datos inexactos o sucios pueden llevar a decisiones erróneas y problemas en el análisis.
2. Calidad de los datos
La calidad de datos se refiere a la medida en que los datos son precisos, confiables, coherentes y adecuados para su propósito previsto en una organización. Es fundamental para asegurar que los datos utilizados para la toma de decisiones, análisis, operaciones y otros procesos sean de alta calidad y reflejen la realidad de manera precisa. La calidad de datos involucra varios aspectos clave, que incluyen:
La mejora de la calidad de datos es esencial para que una organización tome decisiones informadas y obtenga resultados precisos de análisis y procesos. La gestión de calidad de datos implica la implementación de políticas, procesos y tecnologías para mantener y mejorar continuamente la calidad de los datos a lo largo del tiempo.
a. Enriquecimiento de datos
El enriquecimiento de datos es un proceso mediante el cual se agregan o mejoran datos existentes con información adicional, más detallada o relevante. El objetivo principal del enriquecimiento de datos es mejorar la calidad y la utilidad de los datos, lo que puede ayudar a las organizaciones a tomar decisiones más informadas, a comprender mejor a sus clientes y a mejorar la precisión de sus análisis y modelos.
b. Protección de datos
La protección de datos se refiere a las medidas y prácticas diseñadas para garantizar la seguridad, la privacidad y la integridad de la información personal o sensible. Esto es fundamental para proteger la información confidencial de individuos y organizaciones de posibles amenazas y abusos.
Algunos aspectos clave de la protección de datos incluyen:
c. Validación de datos
La validación de datos es un proceso que implica verificar la precisión y la integridad de los datos ingresados o almacenados en un sistema o en una base de datos. El objetivo principal de la validación de datos es garantizar que los datos sean coherentes, confiables y cumplan con ciertos criterios o reglas predefinidas. Este proceso es fundamental para mantener la calidad de los datos y prevenir errores que puedan afectar las operaciones y la toma de decisiones.
Aquí hay algunas técnicas y enfoques comunes en la validación de datos:
La validación de datos es esencial para garantizar la calidad de los datos y evitar problemas como datos incorrectos o inconsistentes que pueden afectar la precisión de los informes, la toma de decisiones y la eficiencia de los procesos empresariales.
3. Gobernanza de datos
La gobernanza de datos es un conjunto de procesos, políticas, estándares y prácticas que se implementan en una organización para garantizar la gestión efectiva, la calidad, la seguridad y el cumplimiento de los datos a lo largo de toda la empresa. El objetivo principal de la gobernanza de datos es establecer un marco sólido que permita a una organización aprovechar al máximo sus datos mientras se minimizan los riesgos y se asegura la integridad y la confidencialidad de la información.
a. Catálogo de datos
Un catálogo de datos es una herramienta o sistema que actúa como un repositorio centralizado de información sobre los datos dentro de una organización. Su propósito principal es proporcionar una visión organizada y detallada de los activos de datos disponibles, lo que facilita su descubrimiento, acceso y gestión.
El catálogo de datos desempeña un papel crucial en la gestión de datos y la gobernanza de datos al proporcionar visibilidad y control sobre los activos de datos de una organización.
b. Linaje de datos
El linaje de datos es un concepto que se refiere al rastreo y la documentación de la procedencia y los cambios que ha experimentado un conjunto de datos a lo largo de su ciclo de vida. En otras palabras, el linaje de datos muestra la historia completa de un dato, desde su origen hasta su estado actual, incluyendo todas las transformaciones y procesos a los que ha sido sometido.
c. Política de datos y flujo de trabajo
Las políticas de datos y los flujos de trabajo de datos son dos componentes esenciales de la gestión de datos en una organización. Juntos, ayudan a definir cómo se manejan, almacenan, protegen y utilizan los datos de manera coherente y eficiente.
d. Política de Datos
Una política de datos es un conjunto de directrices, reglas y principios que establecen cómo se deben administrar y utilizar los datos en una organización. Estas políticas se crean para garantizar la calidad de los datos, la privacidad, la seguridad, la conformidad con las regulaciones y la toma de decisiones basada en datos confiables.
e. Flujo de Trabajo de Datos
Un flujo de trabajo de datos, también conocido como proceso de datos, describe la secuencia de pasos y tareas que se siguen para mover, transformar y utilizar los datos en una organización. Estos flujos de trabajo son esenciales para garantizar que los datos se procesen de manera eficiente y efectiva desde su origen hasta su destino final. Algunos elementos clave de un flujo de trabajo de datos incluyen:
Tanto las políticas de datos como los flujos de trabajo de datos son esenciales para la gestión efectiva de datos en una organización. Las políticas establecen el marco de cómo se deben tratar los datos, mientras que los flujos de trabajo permiten la implementación práctica de esas políticas en la vida cotidiana de la organización.
4. Estado de los datos
El «estado de los datos» se refiere a la condición actual de los datos dentro de una organización o sistema en un momento específico. Describe si los datos son precisos, actualizados, completos, coherentes y disponibles para su uso previsto. El estado de los datos es un indicador crítico de la calidad y la utilidad de la información que una organización utiliza para tomar decisiones, realizar análisis y llevar a cabo sus operaciones.
a. Resultados comerciales
Los «resultados comerciales» se refieren a los logros, métricas y datos que una organización obtiene en el curso de sus operaciones comerciales. Estos resultados comerciales pueden variar según la industria, el tipo de empresa y los objetivos específicos de la organización, pero en general, se utilizan para evaluar el rendimiento y el éxito de la empresa en términos financieros y operativos. Aquí hay algunos ejemplos de resultados comerciales comunes:
b. Preparación de datos y API de datos
La «preparación de datos» y las «API de datos» son dos aspectos importantes en la gestión y el uso efectivo de los datos en una organización. Aquí se describen ambos conceptos:
Preparación de Datos: La preparación de datos es el proceso de limpiar, transformar y organizar los datos para que estén en un formato adecuado y sean utilizables para análisis, informes u otras aplicaciones. Implica una serie de pasos, que incluyen:
API de Datos: Una API de datos, o interfaz de programación de aplicaciones de datos, es un conjunto de reglas y protocolos que permiten que las aplicaciones y sistemas informáticos se comuniquen entre sí y compartan datos de manera estructurada.
c. Alfabetización de datos
La «alfabetización de datos» se refiere a la capacidad de una persona para comprender, analizar y utilizar datos de manera efectiva. Implica la habilidad de leer, interpretar y comunicar información basada en datos de manera crítica y precisa. En un mundo donde los datos desempeñan un papel cada vez más importante en la toma de decisiones, la alfabetización de datos se ha convertido en una habilidad fundamental tanto en el ámbito personal como profesional.
1. Integración de datos
Las organizaciones a menudo tienen datos dispersos en múltiples sistemas. La integración de datos implica la combinación de datos de diferentes fuentes para obtener una visión completa y coherente.

2. Modelado de datos
Los modelos de datos son diagramas simples de sus sistemas y los datos que contienen esos sistemas. El modelado de datos facilita a los equipos ver cómo fluyen los datos a través de sus sistemas y procesos empresariales.
Estos son algunos ejemplos de información que un modelo de datos podría incluir:
3. Almacenamiento de datos
El almacenamiento de datos es la práctica de registrar y preservar datos para el futuro, esto sirve para recabar los datos a lo largo del tiempo. Una vez clasificados ordenadamente, es posible acceder a la información que necesites de forma inmediata y sencilla. En los negocios se usa para realizar consultas que faciliten encontrar soluciones, tomar decisiones y crear estrategias.
Una de sus funciones más importantes es permitir a los negocios generar y recabar bases de contactos, como:
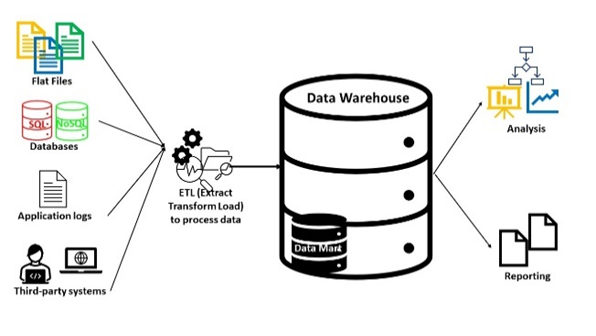
4. Catálogo de datos
Un catálogo de datos es un inventario detallado de todos los activos de datos de una organización, diseñado para ayudar a los profesionales de datos a encontrar rápidamente los datos más apropiados para cualquier propósito comercial o analítico.
Un catálogo de datos utiliza metadatos, datos que describen o resumen datos, para crear un inventario informativo y de búsqueda de todos los activos de datos en una organización. Estos activos pueden incluir:
5. Procesamiento de datos
El procesamiento de datos se refiere al conjunto de acciones y transformaciones que se realizan en datos para convertirlos de su estado original en información útil, significativa y procesable. Esto implica la recopilación, organización, análisis, manipulación y presentación de datos de una manera que permita a las personas, sistemas o aplicaciones tomar decisiones informadas o realizar tareas específicas.
6. La gobernanza de datos
La gobernanza de datos, también conocida como gobierno de datos, es un conjunto de prácticas, políticas, procedimientos y procesos que se utilizan para gestionar y controlar los datos en una organización. El objetivo principal de la gobernanza de datos es garantizar que los datos sean confiables, precisos, seguros y estén disponibles para las personas y sistemas adecuados cuando sea necesario. La gobernanza de datos es esencial para garantizar la calidad de los datos y para cumplir con regulaciones y estándares de privacidad de datos.
7. Gestión del ciclo de vida de los datos (Data Lifecycle Management – DLM)
El DLM se refiere a un enfoque estratégico y práctico para gestionar datos a lo largo de todo su ciclo de vida, desde su creación hasta su eliminación o archivo final.
El ciclo de vida de los datos comprende varias etapas, que pueden variar según la organización y el tipo de datos, pero generalmente incluyen:
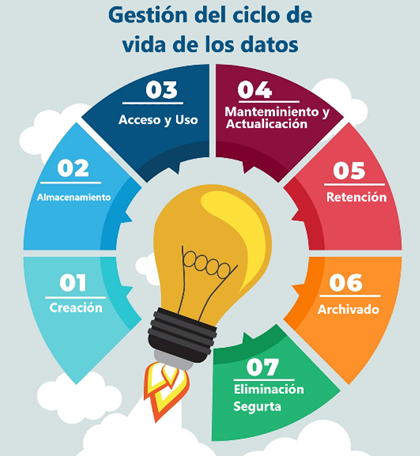
a. Creación: Los datos se crean inicialmente como resultado de una actividad o proceso, como la captura de información de clientes, la generación de registros de transacciones, la recopilación de datos de sensores, etc.
b. Almacenamiento: Los datos se almacenan en sistemas de almacenamiento, ya sea en servidores locales, en la nube o en dispositivos físicos.
c. Acceso y Uso: Los datos se utilizan para diversas actividades, como análisis, informes, toma de decisiones, aplicaciones en tiempo real, entre otros.
d. Mantenimiento y Actualización: Los datos pueden requerir mantenimiento periódico para garantizar su precisión y calidad. Esto puede incluir la actualización de registros, la limpieza de datos duplicados y la corrección de errores.
e. Retención: Los datos deben conservarse durante un período específico para cumplir con regulaciones legales o fines comerciales. Esto puede variar según el tipo de datos y la industria.
f. Archivado: Después de su período de retención, los datos pueden archivarse para su conservación a largo plazo, generalmente en sistemas de almacenamiento de menor costo y acceso más lento.
g. Eliminación Segura: Cuando los datos ya no son necesarios, deben eliminarse de manera segura para proteger la privacidad y la seguridad de la información.
8. Tubería de datos (Data Pipeline – ETL)
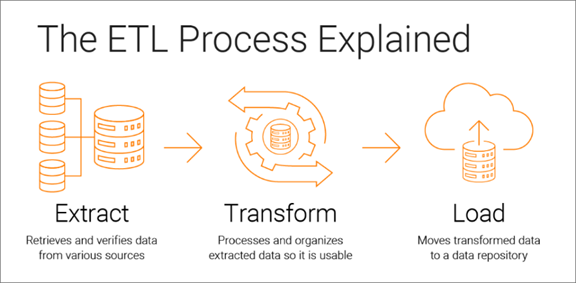
Data Pipeline (también conocido como tubería de datos) es un conjunto de procesos y tecnologías que permiten la extracción, transformación y carga (ETL, por sus siglas en inglés) de datos desde múltiples fuentes de datos a un destino final, como una base de datos, un almacén de datos o un sistema de análisis. Estas tuberías se utilizan para mover datos de un lugar a otro de manera eficiente y confiable, y a menudo forman parte fundamental de la infraestructura de datos en las organizaciones.
Aquí hay una descripción de las tres fases principales de un Data Pipeline:
9. Seguridad de datos
La seguridad de datos, también conocida como ciberseguridad o seguridad de la información, se refiere a las prácticas, medidas y tecnologías diseñadas para proteger los datos y la información de una organización contra amenazas, ataques y accesos no autorizados. La seguridad de datos es fundamental en la actualidad debido a la creciente cantidad de datos digitales almacenados y compartidos en sistemas informáticos y redes.
Aspectos importantes de la seguridad de los datos.

10. Arquitectura de datos
La arquitectura de datos se refiere a la estructura y diseño de cómo una organización almacena, organiza, procesa y gestiona sus datos. Es un componente esencial de la gestión de datos en una empresa o entidad, y su objetivo principal es asegurarse de que los datos estén disponibles, sean accesibles, sean confiables y cumplan con los requisitos comerciales y tecnológicos de la organización.
El gobierno de datos define roles, responsabilidades y procesos para garantizar la rendición de cuentas y la propiedad de los activos de datos en toda la empresa.
El gobierno de datos es un sistema para definir quién dentro de una organización tiene autoridad y control sobre los activos de datos y cómo se pueden usar esos activos de datos. Abarca las personas, los procesos y las tecnologías necesarios para administrar y proteger los activos de datos.
El Data Governance Institute lo define como «un sistema de derechos de decisión y responsabilidades para procesos relacionados con la información, ejecutados de acuerdo con modelos acordados que describen quién puede tomar qué acciones con qué información, y cuándo, bajo qué circunstancias, utilizando qué métodos».
La Data Management Association (DAMA) International lo define como la «planificación, supervisión y control sobre la gestión de datos y el uso de datos y fuentes relacionadas con los datos».
El gobierno de datos puede considerarse mejor como una función que respalda la estrategia general de gestión de datos de una organización. Dicho marco proporciona a su organización un enfoque holístico para recopilar, administrar, proteger y almacenar datos. Para ayudar a comprender lo que debe cubrir un marco, DAMA visualiza la gestión de datos como una rueda, con el gobierno de
datos como el centro desde el cual irradian las siguientes 10 áreas de conocimiento de gestión de datos:
• Arquitectura de datos: la estructura general de los datos y los recursos relacionados con los datos como parte integral de la arquitectura empresarial.
• Modelado y diseño de datos: análisis, diseño, construcción, pruebas y mantenimiento
• Almacenamiento y operaciones de datos: implementación y administración del almacenamiento de activos de datos físicos estructurados
• Seguridad de los datos: garantizar la privacidad, la confidencialidad y el acceso adecuado
• Integración e interoperabilidad de datos: adquisición, extracción, transformación, movimiento, entrega, replicación, federación, virtualización y soporte operativo
• Documentos y contenido: almacenar, proteger, indexar y permitir el acceso a los datos que se encuentran en fuentes no estructuradas y hacer que estos datos estén disponibles para la integración e interoperabilidad con datos estructurados
• Datos maestros y de referencia: gestión de datos compartidos para reducir la redundancia y garantizar una mejor calidad de los datos mediante la definición y el uso estandarizados de los valores de los datos.
• Almacenamiento de datos e inteligencia empresarial (BI): gestión del procesamiento de datos analíticos y habilitación del acceso a los datos de soporte de decisiones para informes y análisis.
• Metadatos: recopilación, categorización, mantenimiento, integración, control, administración y entrega de metadatos
• Calidad de los datos: definir, supervisar, mantener la integridad de los datos y mejorar la calidad de los datos
Al establecer una estrategia, se debe considerar cada una de las facetas anteriores de la recopilación, administración, archivo y uso de datos.
El Business Application Research Center (BARC) advierte que el gobierno de datos es un programa altamente complejo y continuo, no una «iniciativa big bang», y corre el riesgo de que los participantes pierdan confianza e interés con el tiempo. Para contrarrestar eso, BARC recomienda comenzar con un proyecto prototipo manejable o específico de la aplicación y luego expandirse en toda la empresa en función de las lecciones aprendidas.
BARC recomienda los siguientes pasos para la implementación:
• Definir objetivos y comprender los beneficios
• Analizar el estado actual y el análisis delta
• Derivar una hoja de ruta
• Convencer a las partes interesadas y presupuestar el proyecto
• Desarrollar y planificar el programa de gobierno de datos
• Implementar el programa de gobierno de datos
• Monitorizar y controlar
El gobierno de datos es solo una parte de la disciplina general de la gestión de datos, aunque es importante. Mientras que el gobierno de datos se trata de los roles, responsabilidades y procesos para garantizar la rendición de cuentas y la propiedad de los activos de datos, DAMA define la gestión de datos como «un término general que describe los procesos utilizados para planificar, especificar, habilitar, crear, adquirir, mantener, usar, archivar, recuperar, controlar y purgar datos».
Si bien la gestión de datos se ha convertido en un término común para la disciplina, a veces se la conoce como gestión de recursos de datos o gestión de información empresarial (EIM). Gartner describe EIM como «una disciplina integradora para estructurar, describir y gobernar los activos de información a través de los límites organizativos y técnicos para mejorar la eficiencia, promover la transparencia y permitir la visión del negocio».
Importancia de la gobernanza de datos
La mayoría de las empresas ya tienen algún tipo de gobierno para aplicaciones individuales, unidades de negocio o funciones, incluso si los procesos y
responsabilidades son informales. Como práctica, se trata de establecer un control sistemático y formal sobre estos procesos y responsabilidades. Hacerlo puede ayudar a las empresas a seguir siendo receptivas, especialmente a medida que crecen a un tamaño en el que ya no es eficiente para las personas realizar tareas multifuncionales. Varios de los beneficios generales de la gestión de datos solo se pueden obtener después de que la empresa haya establecido un gobierno de datos sistemático. Algunos de estos beneficios incluyen:
• Soporte de decisiones mejor y más completo derivado de datos consistentes y uniformes en toda la organización
• Reglas claras para cambiar procesos y datos que ayudan al negocio y a TI a ser más ágiles y escalables
• Reducción de costos en otras áreas de la gestión de datos a través de la provisión de mecanismos de control central
• Mayor eficiencia a través de la capacidad de reutilizar procesos y datos
• Mayor confianza en la calidad de los datos y la documentación de los procesos de datos
• Mejora del cumplimiento de las normativas sobre datos
El objetivo es establecer los métodos, el conjunto de responsabilidades y los procesos para estandarizar, integrar, proteger y almacenar datos corporativos. Según BARC, los objetivos clave de una organización deben ser:
• Minimice los riesgos
• Establecer reglas internas para el uso de datos
• Implementar requisitos de cumplimiento
• Mejorar la comunicación interna y externa
• Aumentar el valor de los datos
• Facilitar la administración de lo anterior
• Reducir costes
• Ayudar a garantizar la continuidad de la empresa a través de la gestión y optimización de riesgos
BARC señala que tales programas siempre abarcan los niveles estratégico, táctico y operativo en las empresas, y deben tratarse como procesos continuos e iterativos.
Según el Data Governance Institute, ocho principios están en el centro de todos los programas exitosos de gobierno y administración de datos:
1. Todos los participantes deben tener integridad en sus relaciones entre sí. Deben ser veraces y comunicativos al discutir los impulsores, las restricciones, las opciones y los impactos de las decisiones relacionadas con los datos.
2. Los procesos de gobierno y administración de datos requieren transparencia. Debe quedar claro para todos los participantes y auditores cómo y cuándo se introdujeron en los procesos las decisiones y controles relacionados con los datos.
3. Las decisiones, procesos y controles relacionados con los datos sujetos a la gobernanza de datos deben ser auditables. Deben ir acompañados de documentación para respaldar los requisitos de auditoría operativa y basados en el cumplimiento.
4. Deben definir quién es responsable de las decisiones, procesos y controles multifuncionales relacionados con los datos.
5. Debe definir quién es responsable de las actividades de administración que son responsabilidades de contribuyentes individuales y grupos de administradores de datos.
6. Los programas deben definir las responsabilidades de una manera que introduzca controles y equilibrios entre los equipos de negocios y tecnología, y entre aquellos que crean/recopilan información, aquellos que la administran, quienes la usan y aquellos que introducen estándares y requisitos de cumplimiento.
7. El programa debe introducir y apoyar la estandarización de los datos empresariales.
8. Los programas deben apoyar actividades proactivas y reactivas de gestión del cambio para los valores de los datos de referencia y la estructura/uso de datos maestros y metadatos.
Las estrategias de gobierno de datos deben adaptarse para adaptarse mejor a los procesos, necesidades y objetivos de una organización. Aún así, hay seis mejores prácticas básicas que vale la pena seguir:
1. Identificar elementos de datos críticos y tratar los datos como un recurso estratégico.
2. Establecer políticas y procedimientos para todo el ciclo de vida de los datos.
3. Involucrar a los usuarios empresariales en el proceso de gobernanza.
4. No descuides la gestión de datos maestros.
5. Comprender el valor de la información.
6. No restrinja demasiado el uso de datos.
Para obtener más información sobre cómo hacer un gobierno de datos correcto, consulte «6 mejores prácticas para un buen gobierno de datos«.
Un buen gobierno de datos no es una tarea sencilla. Requiere trabajo en equipo, inversión y recursos, así como planificación y monitoreo. Algunos de los principales desafíos de un programa de gobierno de datos incluyen:
• Falta de liderazgo de datos: Al igual que otras funciones comerciales, el gobierno de datos requiere un fuerte liderazgo ejecutivo. El líder debe dar dirección al equipo de gobierno, desarrollar políticas para que todos en la organización las sigan y comunicarse con otros líderes de la empresa.
• Falta de recursos: Las iniciativas de gobierno de datos pueden tener dificultades por la falta de inversión en presupuesto o personal. El gobierno de datos debe ser propiedad y pagado por alguien, pero rara vez genera ingresos por sí solo. Sin embargo, el gobierno de datos y la gestión de datos en general son esenciales para aprovechar los datos para generar ingresos.
• Datos aislados: Los datos tienen una forma de convertirse en silos y segmentados con el tiempo, especialmente a medida que las líneas de negocio u otras funciones desarrollan nuevas fuentes de datos, aplican nuevas tecnologías y similares. Su programa de gobierno de datos necesita romper continuamente nuevos silos.
Para obtener más información sobre estas dificultades y otras, consulte «7 errores de gobierno de datos que debe evitar«.
El gobierno de datos es un programa continuo en lugar de una solución tecnológica, pero existen herramientas con características de gobierno de datos que pueden ayudar a respaldar su programa. La herramienta que se adapte a su empresa dependerá de sus necesidades, volumen de datos y presupuesto. Según PeerSpot, algunas de las soluciones más populares incluyen:
Solución de gobierno de datos
Gobernanza de Collibra: Collibra es una solución para toda la empresa que automatiza muchas tareas de gobierno y administración. Incluye un administrador de políticas, un servicio de asistencia de datos, un diccionario de datos y un glosario empresarial.
Gestión de datos SAS: Construido sobre la plataforma SAS, SAS Data Management proporciona una GUI basada en roles para administrar procesos e incluye un glosario empresarial integrado, administración de metadatos SAS y de terceros, y visualización de linaje.
Erwin Data Intelligence (DI) para el gobierno de datos: Erwin DI combina el catálogo de datos y las capacidades de alfabetización de datos para proporcionar conocimiento y acceso a los activos de datos disponibles. Proporciona orientación sobre el uso de esos activos de datos y garantiza que se sigan las políticas de datos y las mejores prácticas.
Informatica Axon: Informatica Axon es un centro de recopilación y un mercado de datos para programas de soporte. Las características clave incluyen un glosario empresarial colaborativo, la capacidad de visualizar el linaje de datos y generar mediciones de calidad de datos basadas en definiciones comerciales.
SAP Data Hub: SAP Data Hub es una solución de orquestación de datos destinada a ayudarle a descubrir, refinar, enriquecer y gobernar todos los tipos, variedades y volúmenes de datos en todo su entorno de datos. Ayuda a las organizaciones a establecer configuraciones de seguridad y directivas de control de identidad para usuarios, grupos y roles, y a optimizar las prácticas recomendadas y los procesos para la administración de directivas y el registro de seguridad.
Alatión: es un catálogo de datos empresariales que indexa automáticamente los datos por origen. Una de sus capacidades clave, TrustCheck, proporciona «barandillas» en tiempo real a los flujos de trabajo. Diseñado específicamente para admitir el análisis de autoservicio, TrustCheck adjunta pautas y reglas a los activos de datos.
Suite de gobierno de datos Varonis: La solución de Varonis automatiza las tareas de protección y gestión de datos aprovechando un marco de metadatos escalable que permite a las organizaciones administrar el acceso a los datos, ver pistas de auditoría de cada evento de archivo y correo electrónico, identificar la propiedad de los datos en diferentes unidades de negocio y encontrar y clasificar datos y documentos confidenciales.
Gobierno de datos de IBM: IBM Data Governance aprovecha el aprendizaje automático para
Gobierno de datos recopilar y seleccionar activos de datos. El catálogo de datos integrado ayuda a las empresas a encontrar, seleccionar, analizar, preparar y compartir datos.
El gobierno de datos es un sistema, pero hay algunas certificaciones que pueden ayudar a su organización a obtener una ventaja, incluidas las siguientes:
• DAMA Certified Data Management Professional (CDMP)
• Profesional de Gobierno y Administración de Datos (DGSP)
• Gestión de datos empresariales de edX
• SAP Certified Application Associate – SAP Master Data Governance
Para obtener certificaciones relacionadas, consulte «10 certificaciones de administración de datos maestros que darán sus frutos«.
Cada empresa compone su gobierno de datos de manera diferente, pero hay algunos puntos en común.
Comité directivo: Los programas de gobierno abarcan toda la empresa, generalmente comenzando con un comité directivo compuesto por altos directivos, a menudo individuos de nivel C o vicepresidentes responsables de las líneas de negocio. Morgan Templar, autor de Get Governed: Building World Class Data Governance Programs, dice que las responsabilidades de los miembros del comité directivo incluyen establecer la estrategia general de gobierno con resultados específicos, defender el trabajo de los administradores de datos y responsabilizar a la organización de gobierno de los plazos y resultados.
Propietario de los datos: Templar dice que los propietarios de datos son individuos responsables de garantizar que la información dentro de un dominio de datos específico se rija a través de sistemas y líneas de negocio. Generalmente son miembros del comité directivo, aunque pueden no ser miembros con derecho a voto. Los titulares de los datos son responsables de:
• Aprobación de glosarios de datos y otras definiciones de datos
• Garantizar la precisión de la información en toda la empresa
• Actividades directas de calidad de datos
• Revisar y aprobar enfoques, resultados y actividades de gestión de datos maestros
• Trabajar con otros propietarios de datos para resolver problemas de datos
• Revisión de segundo nivel para los problemas identificados por los administradores de datos
• Proporcionar al comité directivo información sobre soluciones de software, políticas o requisitos reglamentarios de su dominio de datos
Administrador de datos:Los administradores de datos son responsables de la gestión diaria de los datos. Son expertos en la materia (PYME) que entienden y comunican el significado y el uso de la información, dice Templar, y trabajan con otros administradores de datos en toda la organización como el órgano rector de la
mayoría de las decisiones de datos. Los administradores de datos son responsables de:
• Ser pymes para su dominio de datos
• Identificar problemas de datos y trabajar con otros administradores de datos para resolverlos
• Actuar como miembro del consejo de administradores de datos
• Propuesta, discusión y votación de políticas de datos y actividades del comité
• Informar al propietario de los datos y otras partes interesadas dentro de un dominio de datos
• Trabajar de forma multifuncional en todas las líneas de negocio para garantizar que los datos de su dominio se administren y comprendan
La explosión de la inteligencia artificial está haciendo que la gente se replantee lo que nos hace únicos. Llámalo el efecto IA.
La inteligencia artificial ha dado saltos impresionantes en el último año. Los algoritmos ahora están haciendo cosas, como diseñar drogas, escribir votos matrimoniales, negociar acuerdos, crear ilustraciones, componer música, que siempre han sido prerrogativa exclusiva de los humanos.
Ha habido mucha especulación vertiginosa sobre las implicaciones económicas de todo esto. (¡La IA nos hará tremendamente productivos! ¡La IA nos robará nuestros trabajos!) Sin embargo, el advenimiento de la IA sofisticada plantea otra gran pregunta que ha recibido mucha menos atención: ¿Cómo cambia esto nuestro sentido de lo que significa ser humano? Frente a máquinas cada vez más inteligentes, ¿seguimos siendo… bueno, ¿especial?
«La humanidad siempre se ha visto a sí misma como única en el universo», dice Benoît Monin, profesor de comportamiento organizacional en la Escuela de Negocios de Stanford. «Cuando el contraste era con los animales, señalamos nuestro uso del lenguaje, la razón y la lógica como rasgos definitorios. Entonces, ¿qué sucede cuando el teléfono en tu bolsillo de repente es mejor que tú en estas cosas?»
Monin y Erik SantoroAbrir en una ventana nueva, entonces candidato a doctorado en psicología social en Stanford, comenzaron a hablar de esto hace unos años, cuando un programa llamado AlphaGo estaba golpeando a los mejores jugadores del mundo en el complejo juego de estrategia Go. Lo que les intrigaba era cómo reaccionaba la gente a las noticias.
«Nos dimos cuenta de que cuando discutían estos hitos, la gente a menudo parecía estar a la defensiva», dice Santoro, quien obtuvo su doctorado esta primavera y pronto comenzará un postdoctorado en la Universidad de Columbia. «La charla gravitaría hacia lo que la IA aún no podía hacer, como si quisiéramos asegurarnos de que nada había cambiado realmente».
Y con cada nuevo avance, agrega Monin, llegó el estribillo: «Oh, eso no es inteligencia real, es solo mimetismo y coincidencia de patrones», ignorando el hecho de que los humanos también aprenden por imitación, y tenemos nuestra propia parte de heurísticas defectuosas, sesgos y atajos que están muy por debajo del razonamiento objetivo.
Esto sugería que, si los humanos se sentían amenazados por las nuevas tecnologías, se trataba de algo más que la seguridad de sus cheques de pago. Tal vez la gente estaba ansiosa por algo más profundamente personal: su sentido de identidad y su relevancia en el gran esquema de las cosas.
Hay un modelo bien establecido en psicología llamado teoría de la identidad social. La idea es que los humanos se identifiquen con un grupo elegido y se definan a sí mismos en contraste con los grupos externos. Es ese instinto profundamente arraigado de nosotros contra ellos lo que impulsa tanto conflicto social.
«Pensamos, tal vez la IA es un nuevo grupo de referencia», dice Monin, «especialmente porque se presenta como que tiene rasgos similares a los humanos». Él y Santoro se preguntaban: si el sentido de singularidad de las personas se ve amenazado, ¿tratarán de distinguirse de sus nuevos rivales cambiando sus criterios de lo que significa ser humano, en efecto, moviendo los postes de la meta?
Para averiguarlo, Santoro y Monin elaboraron una lista de 20 atributos humanos, 10 de los cuales actualmente compartimos con AI. Los otros 10 eran rasgos que sentían que eran distintivos de los humanos.
Encuestaron a 200 personas sobre cuán capaces pensaban que eran los humanos y la IA en cada rasgo. Los encuestados calificaron a los humanos como más capaces en los 20 rasgos, pero la brecha fue pequeña en los rasgos compartidos y bastante grande en los distintivos, como se esperaba.
Ahora para la prueba principal: los investigadores dividieron alrededor de 800 personas en dos grupos. La mitad leyó un artículo titulado «La revolución de la inteligencia artificial», mientras que un grupo de control leyó un artículo sobre los notables atributos de los árboles. Luego, volviendo a la lista de 20 atributos humanos, se les pidió a los sujetos de prueba que calificaran «cuán esencial» es cada uno para ser humano.
Efectivamente, las personas que leen sobre IA calificaron atributos distintivamente humanos como la personalidad, la moralidad y las relaciones como más esenciales que aquellos que leyeron sobre árboles. Frente a los avances de la IA, el sentido de la naturaleza humana de las personas se redujo para enfatizar los rasgos que las máquinas no tienen. Monin y Santoro llamaron a esto el Efecto IA.
Para descartar otras explicaciones, realizaron varios experimentos más. En uno, a los participantes simplemente se les dijo que la IA estaba mejorando. «El mismo resultado», dice Monin. «Cada vez que mencionamos los avances en IA, obtuvimos este aumento en la importancia de los atributos humanos distintivos».
Sorprendentemente, los participantes no minimizaron los rasgos compartidos por los humanos y la IA, como los investigadores habían predicho que lo harían. «Entonces, incluso si los humanos ya no son los mejores en lógica, no dijeron que la lógica es menos central para la naturaleza humana», señala Santoro.
Por supuesto, la inteligencia artificial no es exactamente como una tribu invasora con modales extranjeros; después de todo, la creamos para ser como nosotros. (Las redes neuronales, por ejemplo, están inspiradas en la arquitectura del cerebro humano). Pero hay una ironía aquí: las habilidades cognitivas y el ingenio que hicieron posible la IA son ahora el terreno en el que las máquinas nos están superando. Y como sugieren los hallazgos de la presente investigación, eso puede llevarnos a dar más valor a otros rasgos.
También vale la pena señalar que esas habilidades cognitivas aún tienen un alto estatus y salario. ¿Podría eso cambiar si las habilidades blandas como la calidez y la empatía, la capacidad de fomentar el crecimiento en los demás, se valoran más? ¿Se pagará menos a los abogados y quants, mientras que los maestros y cuidadores recibirán más respeto y dinero?
«Esa es ciertamente una posible implicación de nuestro trabajo», dice Monin. «Hay una gran cantidad de competencias que no solo no serán asumidas por la IA, sino que la gente va a valorar cada vez más. En un mundo de IA ubicua y capaz, las habilidades interpersonales probablemente serán cada vez más buscadas por los empleadores».
Mientras tanto, dice, es probable que el efecto de la IA esté creciendo. «Desde que realizamos esta investigación, el mundo real ha superado todo lo que podríamos haber imaginado. Ha sido un aluvión constante de información sobre nuevos logros en IA. Así que todo lo que vimos en nuestra pequeña versión en el laboratorio probablemente ya esté sucediendo a una escala mucho más amplia en la sociedad».

El aprendizaje automático (ML) y la inteligencia artificial (IA) han recibido mucho interés público en los últimos años, y ambos términos son prácticamente comunes en el lenguaje de TI. A pesar de sus similitudes, existen algunas diferencias importantes entre ML e IA que con frecuencia se descuidan.
Por lo tanto, cubriremos las diferencias clave entre ML e IA en este blog para que pueda comprender cómo varían estas dos tecnologías y cómo se pueden utilizar juntas.
¡Comencemos!
Descripción del aprendizaje automático (ML)
El aprendizaje automático (ML) es un subcampo de la inteligencia artificial (IA) que automatiza el análisis y la predicción de datos utilizando algoritmos y modelos estadísticos. Permite que los sistemas reconozcan patrones y correlaciones en grandes cantidades de datos y se puede aplicar a una variedad de aplicaciones como el reconocimiento de imágenes, el procesamiento del lenguaje natural y otros.
ML se trata fundamentalmente de aprender de los datos. Es un método continuo de desarrollo de algoritmos que pueden aprender de datos pasados y predecir datos futuros. En este enfoque, los algoritmos de ML pueden mejorar continuamente su rendimiento a lo largo del tiempo al descubrir patrones previamente desconocidos o indetectables.
Tipos de algoritmos de aprendizaje automático
Comúnmente hay 4 tipos de algoritmos de aprendizaje automático. Conozcamos cada uno de ellos.
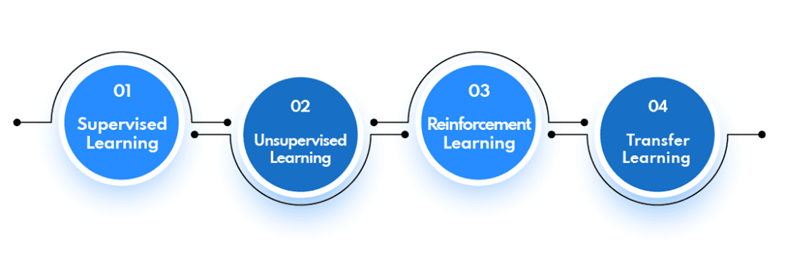
1. Aprendizaje supervisado
El aprendizaje supervisado incluye proporcionar al sistema ML datos etiquetados, lo que le ayuda a comprender cómo las variables únicas se conectan entre sí. Cuando se le presentan nuevos puntos de datos, el sistema aplica este conocimiento para hacer predicciones y decisiones.
2. Aprendizaje no supervisado
A diferencia del aprendizaje supervisado, el aprendizaje no supervisado no necesita datos etiquetados y utiliza varios métodos de agrupación para detectar patrones en grandes cantidades de datos no etiquetados.
3. Aprendizaje por refuerzo
El aprendizaje por refuerzo implica entrenar a un agente para actuar en un contexto específico recompensándolo o castigándolo por sus acciones.
4. Aprendizaje de transferencia
El aprendizaje de transferencia incluye el uso del conocimiento de actividades anteriores para aprender nuevas habilidades de manera eficiente.
Ahora, para tener más comprensión, exploremos algunos ejemplos de aprendizaje automático.
Ejemplos de aprendizaje automático
Entendamos el aprendizaje automático más claramente a través de ejemplos de la vida real.
1. Reconocimiento de imágenes: el aprendizaje automático se aplica en fotografías y videos para reconocer objetos, personas, puntos de referencia y otros elementos visuales. Google Fotos utiliza ML para comprender rostros, ubicaciones y otros elementos en las imágenes para que puedan buscarse y clasificarse convenientemente.
2. Procesamiento del lenguaje natural (PNL): La PNL permite a las máquinas interpretar el lenguaje como lo hacen los humanos. Los chatbots automatizados de servicio al cliente, por ejemplo, utilizan algoritmos de ML para responder consultas de manera confiable al comprender el texto y reconocer el propósito detrás de él.
3. Reconocimiento de voz: ML se utiliza para permitir que las computadoras entiendan los patrones de habla. Esta tecnología se utiliza para aplicaciones de reconocimiento de voz como Alexa de Amazon o Siri de Apple.
4. Motores de recomendación: los algoritmos de aprendizaje automático identifican patrones en los datos y hacen sugerencias basadas en esos patrones. Netflix, por ejemplo, aplica algoritmos de aprendizaje automático para sugerir películas o programas de televisión a los espectadores.
5. Coches autónomos: El aprendizaje automático está en el corazón de los coches autónomos. Se utiliza para la detección de objetos y la navegación, lo que permite a los automóviles identificar y navegar alrededor de los obstáculos en su entorno.
Ahora, esperamos que obtenga una comprensión clara del aprendizaje automático. Ahora, es el momento perfecto para explorar la Inteligencia Artificial (IA). Entonces, sin más preámbulos, profundicemos en la IA.
Comprender la inteligencia artificial (IA)
La inteligencia artificial (IA) es un tipo de tecnología que intenta replicar las capacidades de la inteligencia humana, como la resolución de problemas, la toma de decisiones y el reconocimiento de patrones. En previsión de las circunstancias cambiantes y los nuevos conocimientos, los sistemas de IA están diseñados para aprender, razonar y autocorregirse.
Los algoritmos en los sistemas de IA utilizan conjuntos de datos para obtener información, resolver problemas y elaborar estrategias de toma de decisiones. Esta información puede provenir de una amplia gama de fuentes, incluidos sensores, cámaras y comentarios de los usuarios.
La IA ha existido durante varias décadas y ha crecido en sofisticación con el tiempo. Se utiliza en diversas industrias, incluyendo la banca, la atención médica, la fabricación, el comercio minorista e incluso el entretenimiento. La IA está transformando rápidamente la forma en que las empresas funcionan e interactúan con los clientes, lo que la convierte en una herramienta indispensable para muchas empresas.
En el mundo moderno, la IA se ha vuelto más común que nunca. Las empresas están recurriendo a tecnologías impulsadas por IA, como el reconocimiento facial, el procesamiento del lenguaje natural (NLP), los asistentes virtuales y los vehículos autónomos para automatizar procesos y reducir costos.
En última instancia, la IA tiene el potencial de revolucionar muchos aspectos de la vida cotidiana al proporcionar a las personas soluciones más eficientes y efectivas. A medida que la IA continúa evolucionando, promete ser una herramienta invaluable para las empresas que buscan aumentar su ventaja competitiva.
Tenemos muchos ejemplos de IA asociados con nuestra vida cotidiana. Exploremos algunos de ellos:
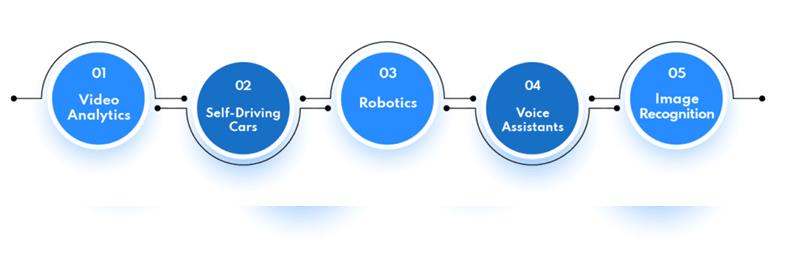
Se utilizan en centros comerciales para ayudar a los clientes y en fábricas para ayudar en las operaciones diarias. Además, también puede contratar desarrolladores de IA para desarrollar robots impulsados por IA para sus negocios. Además de estos, los robots impulsados por IA también se utilizan en otras industrias, como el ejército, la salud, el turismo y más.
4. Asistentes de voz: La inteligencia artificial es utilizada por asistentes de voz virtuales como Siri, Alexa y Google Home para comprender los comandos de lenguaje natural y responder adecuadamente.
El procesamiento del lenguaje natural (NLP) es utilizado por estos asistentes de voz para comprender los comandos del usuario y responder con información pertinente.
5. Reconocimiento de imágenes: El reconocimiento de imágenes es un tipo de aplicación de inteligencia artificial (IA) que utiliza redes neuronales como una forma de reconocer objetos en una imagen o cuadro de video. Se puede utilizar en tiempo real para identificar objetos, emociones e incluso gestos.
Los ejemplos de IA y aprendizaje automático son bastante similares y confusos. Ambos parecen similares a primera vista, pero en realidad, son diferentes.
De hecho, el aprendizaje automático es un subconjunto de la inteligencia artificial. Para explicar esto más claramente, diferenciaremos entre IA y aprendizaje automático.
Aprendizaje Automático s Inteligencia Artificial: ¡las diferencias clave!
El aprendizaje automático (ML) y la inteligencia artificial (IA) son dos conceptos relacionados pero diferentes. Si bien ambos se pueden usar para construir soluciones informáticas potentes, tienen algunas diferencias importantes.
1. Enfoque:
Una de las principales diferencias entre ML e IA es su enfoque. El aprendizaje automático se centra en el desarrollo de sistemas que puedan aprender de los datos y hacer predicciones sobre resultados futuros. Esto requiere algoritmos que puedan procesar grandes cantidades de datos, identificar patrones y generar información a partir de ellos.
La IA, por otro lado, implica la creación de sistemas que pueden pensar, razonar y tomar decisiones por sí mismos. En este sentido, los sistemas de IA tienen la capacidad de «pensar» más allá de los datos que se les dan y proponer soluciones que son más creativas y eficientes que las derivadas de los modelos de ML.
2. Tipo de problemas que resuelven:
Otra diferencia entre ML e IA son los tipos de problemas que resuelven. Los modelos de ML se utilizan normalmente para resolver problemas predictivos, como predecir los precios de las acciones o detectar fraude.
Sin embargo, la IA se puede utilizar para resolver problemas más complejos, como el procesamiento del lenguaje natural y las tareas de visión por computadora.
3. Consumo de energía informática:
Finalmente, los modelos de ML tienden a requerir menos potencia de cálculo que los algoritmos de IA. Esto hace que los modelos de ML sean más adecuados para aplicaciones donde el consumo de energía es importante, como en dispositivos móviles o dispositivos IoT.
En palabras sencillas, el aprendizaje automático y la inteligencia artificial son campos relacionados pero distintos. Tanto AI como ML se pueden usar para crear soluciones informáticas potentes, pero tienen diferentes enfoques y tipos de problemas que resuelven y requieren diferentes niveles de potencia informática.

Por otro lado, la IA enfatiza el desarrollo de máquinas de autoaprendizaje que pueden interactuar con el entorno para identificar patrones, resolver problemas y tomar decisiones.
Ambos son importantes para las empresas, y es importante comprender las diferencias entre los dos para aprovechar sus beneficios potenciales. Por lo tanto, es el momento adecuado para ponerse en contacto con una empresa de desarrollo de aplicaciones de IA, equipar su negocio de IA y aprendizaje automático y disfrutar de los beneficios de estas tecnologías.
La representación de datos mediante gráficos como tablas, diagramas, infografías, mapas de calor, nubes de burbujas, diagramas de dispersión y gráficos mekko se denomina visualización de datos. Estas pantallas visuales y la representación de la información ayudan a comunicar relaciones de datos complejas y conocimientos basados en datos de una manera que facilita la comprensión y la base de decisiones.
El objetivo de la visualización de datos es ayudar a identificar patrones y tendencias a partir de grandes conjuntos de datos. Los datos se refieren al procesamiento de las visualizaciones inmersivas e interactivas que muestran los datos nuevos a medida que se transmiten. Hay un gran volumen de datos disponibles en la actualidad, y para obtener algún beneficio de esa abundancia de datos, el análisis en tiempo real se ha vuelto extremadamente necesario para que las empresas obtener una ventaja sobre su competencia. Las visualizaciones en tiempo real pueden ser muy útiles para las empresas que deben tomar decisiones estratégicas o sobre la marcha.
Es útil para las empresas que necesitan lidiar con el riesgo, tanto administrándolo como respondiendo si algo sale mal. Y, para aquellas empresas que pueden usar estas visualizaciones en tiempo real para aprovechar las oportunidades emergentes antes de que alguien más lo haga. Las visualizaciones en tiempo real funcionan mejor cuando la acción basada en entradas debe tomarse de inmediato al proporcionar contexto a los tomadores de decisiones.
Beneficios comerciales de la visualización de datos:
Procesamiento de información: Con un flujo constante de datos que se generan en tiempo real, es imposible procesarlos y darles sentido con solo mirarlos. La visualización ayuda a dar sentido al desorden de números y texto de una mejor manera. También es más fácil absorber e interpretar los datos cuando se presentan visualmente.
Perspectivas relevantes: La visualización de datos brinda información relevante al conectar y mostrar patrones de cómo se conectan los diferentes conjuntos de datos. Esto puede ayudar a identificar y extraer fácilmente tendencias y patrones que, de otro modo, no serían visibles a partir de los datos sin procesar. Esto es especialmente importante cuando se presentan datos de transmisión y se pueden pronosticar tendencias utilizando visualizaciones en tiempo real.
En los sistemas comerciales financieros, tales visualizaciones de datos en tiempo real pueden mostrar el ROI, las ganancias y las pérdidas en tiempo real y ayudar a las empresas a tomar decisiones inmediatas.
Operaciones comerciales: las visualizaciones de datos ofrecen a las empresas una visión general de la relación actual entre varias secciones y operaciones del negocio. Ayuda en el proceso de toma de decisiones y en la gestión de métricas comerciales críticas. Puede ayudar a revisar y analizar áreas de mejora.
Toma de decisiones: El patrón se vuelve más claro con la visualización de datos, lo que facilita la toma de decisiones más rápidas. Dado que existe una sincronización entre los datos en tiempo real y su visualización, las empresas pueden tomar decisiones rápidas que pueden afectar significativamente a la organización.
Análisis de clientes: La visualización de datos en tiempo real ayuda a analizar los datos de los clientes para comprender la tendencia del negocio. Puede revelar información sobre la comprensión y el conocimiento del público objetivo, sus preferencias y más. Tales conocimientos pueden ser útiles en el diseño de estrategias que puedan abordar los requisitos del cliente.
Ahorra tiempo: Es más fácil de entender, procesar y tomar decisiones basadas en datos representados gráficamente en lugar de pasar por toneladas de informes con datos sin procesar y generar informes a tiempo. Las visualizaciones de datos en tiempo real ayudan a ahorrar tiempo al categorizar y mostrar tendencias y patrones en tiempo real.
Interacción de datos: La visualización de datos ayuda a agrupar y categorizar datos y alienta a los empleados a dedicar tiempo a la interacción de datos a través de la visualización de datos. Esto conduce a mejores ideas y ayuda en la resolución de problemas. Ayuda a diseñar y crear soluciones comerciales procesables.
La visualización de datos en tiempo real proporciona un contexto adicional para los responsables de la toma de decisiones que necesitan responder de inmediato cuando se enfrentan a un riesgo y también para aquellas empresas que necesitan tomar decisiones rápidas antes de perder una oportunidad.
Algunos de los casos de uso para visualizaciones de datos en tiempo real son:
Conclusión
Los datos son la clave para la toma de decisiones en cualquier negocio. Ayudar al proceso de toma de decisiones mediante la representación activa de datos en tiempo real mediante el uso de diferentes métodos de visualización y representación en tiempo real puede brindarle a la empresa una ventaja competitiva ganadora.

